

GPT-4 is Getting Faster 🐇

Over the past few months, we've been keenly observing latencies for both GPT 3.5 & 4. The emerging patterns have been intriguing.
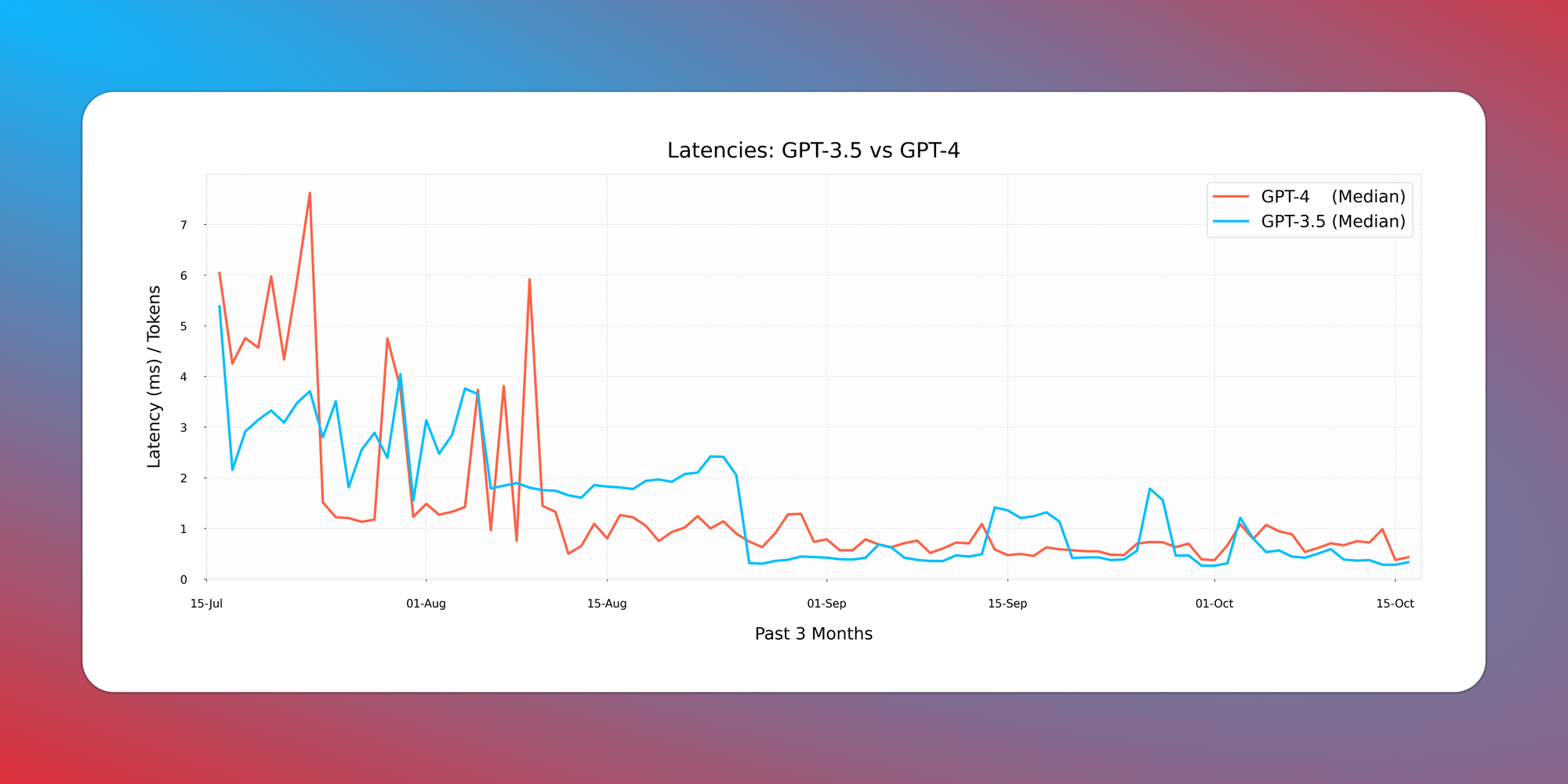
The standout observation? GPT-4 is catching up in speed, closing the latency gap with GPT 3.5.
Our findings reveal a consistent decline in GPT-4 latency. While your mileage might vary based on the specific prompts, the general trend is clear, as illustrated in the following plot showcasing median requests over a three-month period.
But what factors contribute to latency? Let's break it down:
- Round trip time: Typically around 100-200ms
- Queuing time: Ranges between 100-500ms
- Processing time: This can vary significantly based on the complexity and length of your prompt
It's worth noting that a high token count doesn’t always translate to a slower response. For instance, a prompt with 204 tokens, despite being simple, can receive a response in a brisk 4.5 seconds. On the other hand, a 33-token prompt, if complex, might take a whole 32 seconds to process.
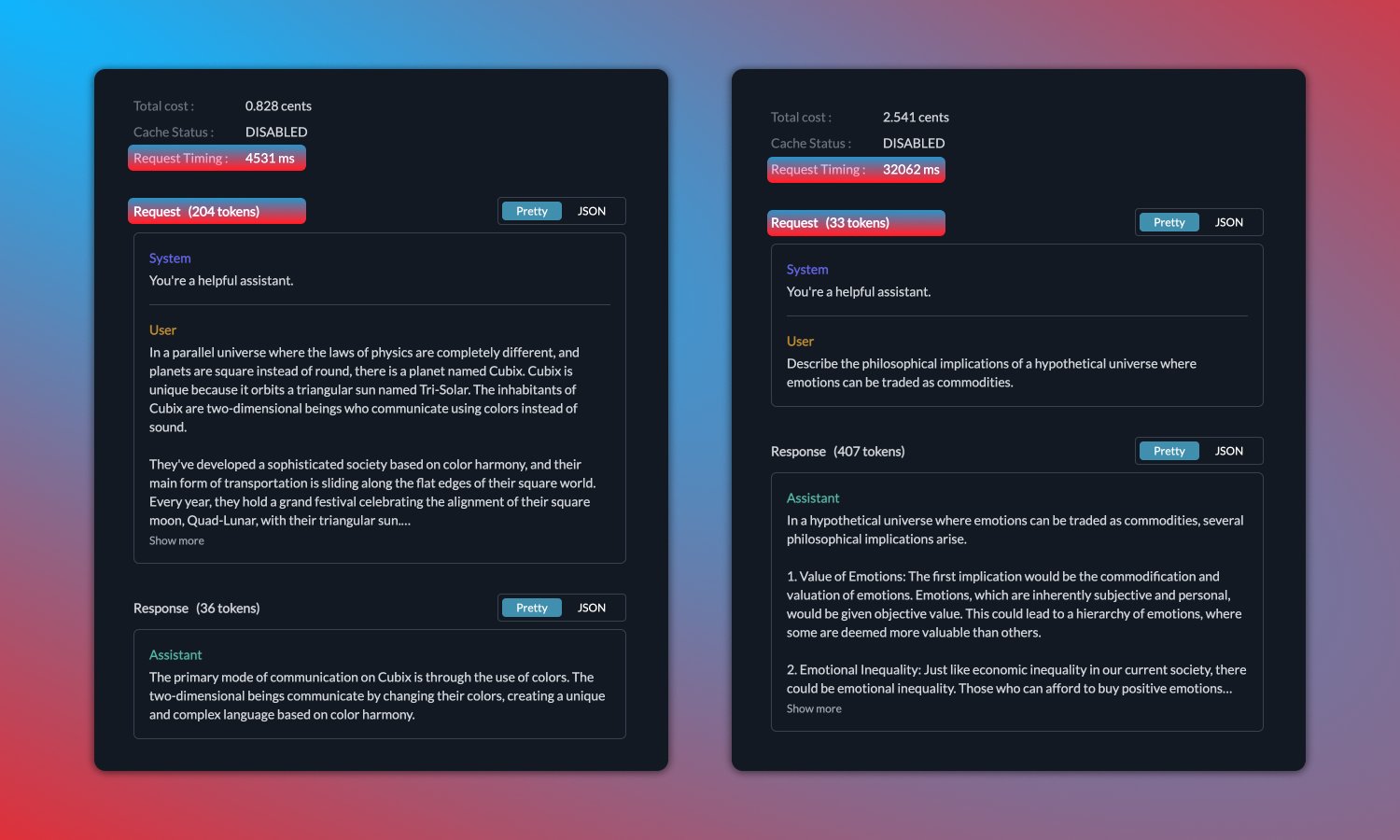
So, we observed Latency/Total Tokens ratios for median and 99 percentile requests.
Median request latencies remain consistent across both models, staying under 1 ms per token.
However, the real surprise comes with the 99th percentile, where latencies have more than halved in just three months!
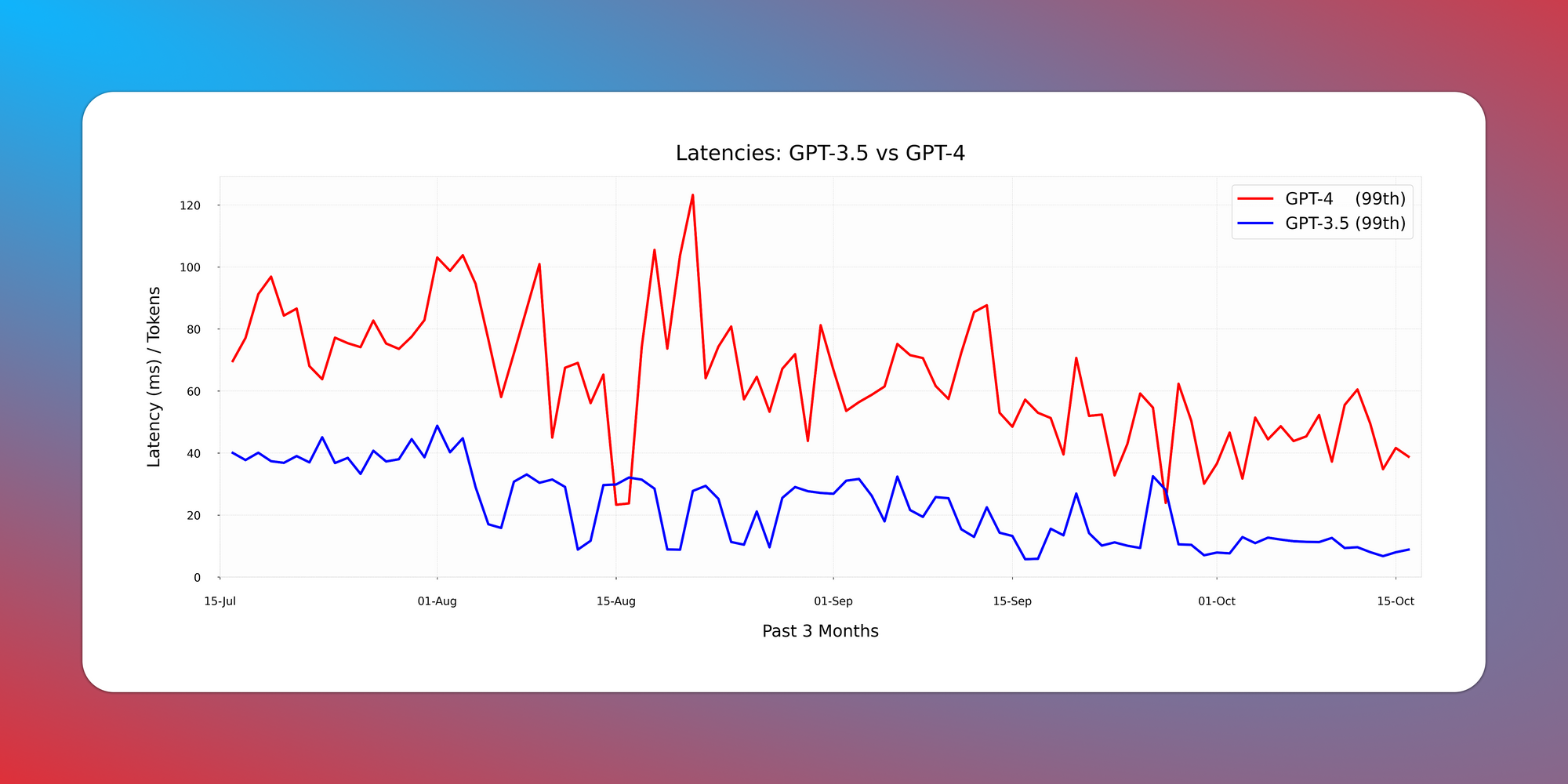
GPT-4 is costlier still, but it’s not slower anymore for majority of your requests. 🐢
We're also exploring another intriguing aspect: Does your latency increase as you get near your rate limits? i.e. does OpenAI deliberately slow you down?
Stay tuned for our next deep dive!
