How to balance AI model accuracy, performance, and costs with an AI gateway Finding the sweet spot between model accuracy, performance, and costs is one of the biggest headaches AI teams face today. See how an AI gateway can solve for that.
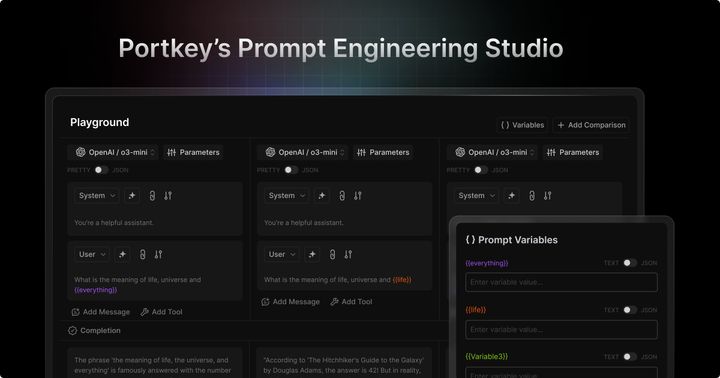
Launching Prompt Engineering Studio Bridging the Chasm: How Portkey's Prompt Engineering Studio Takes AI from Experiment to Production
OpenAI's New Agent Tools: Navigating Strategic Implications for Enterprise AI OpenAI just redefined how enterprises build AI agents—with new Responses APIs, built-in tool integrations, and building blocks for agents. For enterprises invested in AI, these launches bring exciting capabilities and strategic dilemmas: How should enterprises adapt without becoming overly dependent on OpenAI? What does this mean for enterprises invested
The State of AI FinOps 2025: Key Insights from FinOps Foundation's Latest Report AI spending has doubled in enterprise environments, with a clear focus on establishing fundamentals before optimization. Dive into the latest FinOps Foundation report to understand how organizations are managing their AI infrastructure costs and what this means for your GenAI initiatives. This is a summary blog focusing on AI trends
Open WebUI vs LibreChat: Choose the Right ChatGPT UI for Your Organization Every organization wants to harness AI's transformative power. But the real challenge isn't accessing AI – it's doing so while maintaining complete control over your data. For healthcare providers handling patient records, financial institutions managing transactions, or companies navigating GDPR, this isn't just a technical preference – it's a business imperative. While
Beyond Implementation: Why Audit Logs are Critical for Enterprise AI Governance The race to implement Gen AI in enterprise environments has surfaced a critical challenge: As organizations scale their AI operations, maintaining visibility and control across the org becomes increasingly complex. Gone are the days when AI implementation was just about getting LLMs to work - today's enterprise AI infrastructure demands
Portkey in September New security goodies, cool APIs, and more AI models supported. Plus, we're teaming up with MongoDB and LibreChat.