Why LLM security is non-negotiable
Learn how Portkey helps you secure LLM prompts and responses out of the box with built-in AI guardrails and seamless integration with Prompt Security

The rise of LLM-powered applications has unlocked a new wave of productivity and automation. From chatbots and virtual agents to complex multi-step workflows, natural language is now a first-class interface. But as with any interface exposed to end-users, it comes with its own set of risks, and in the case of LLMs, those risks are often overlooked.
LLMs respond to the prompts they receive. If a malicious actor can manipulate that prompt, they can potentially override system instructions, extract sensitive data, or force the model to behave in unintended ways. These vulnerabilities aren’t just theoretical; they’re happening in real-world systems.
Common threats include:
- Prompt injection: Users embed hidden instructions in their input to override or subvert system behavior.
- Jailbreaking: Prompts crafted to bypass content filters and force the model to return restricted or harmful outputs.
- Prompt leakage: Exposure of confidential context like system prompts, API keys, or internal configurations.
These risks aren’t always visible during development; they emerge when your app is in the wild, exposed to real user inputs and unpredictable contexts.
The growing complexity of LLM security
It’s easy to assume that filtering inputs or setting basic model parameters is enough to ensure safe behavior. But security is about understanding how subtle prompt manipulations, context bleeding, or clever phrasing can lead to unintended model behavior.
What makes this even more challenging:
- Prompts and responses are dynamic — what’s safe in one context might be dangerous in another.
- Attacks are getting more sophisticated — from nested instructions to token smuggling.
- Traditional input sanitization or regex-based filters just don’t cut it anymore.
That’s why robust, real-time AI guardrails are essential to monitor and intervene at both ends of the LLM workflow: what the user sends in, and what the model sends back.
And with Portkey, these protections are built in and get even more powerful with its integration into specialized AI guardrail tools.
Why AI guardrails belong in the Gateway
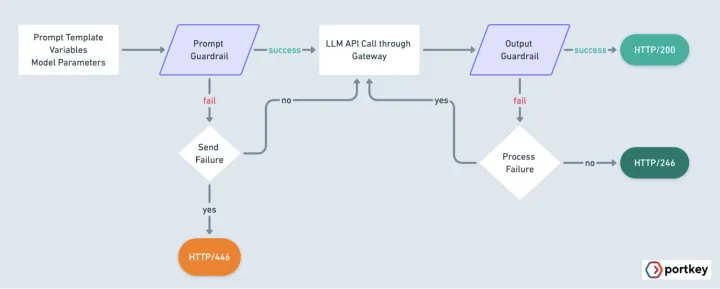
At Portkey, we believe AI guardrails should be enforced at the infrastructure layer, where every LLM call flows through. That’s why guardrails are natively supported in the Portkey Gateway.
With guardrails inside the AI Gateway, you can intercept, evaluate, and act on both prompts and responses in real-time based on custom rules or policy logic. Whether it’s filtering out unsafe input, blocking harmful model output, or applying dynamic routing based on content, Portkey gives you full control over LLM behavior without manual patchwork.
But we’re also going a step further.
To make it even easier to secure your AI stack, Portkey now integrates with Prompt Security, one of the leading platforms for AI Security.
This integration unlocks two critical protections:
- Protect Prompt – Evaluate and sanitize the user’s prompt before it reaches the model
- Protect Response – Review and filter the model’s output before it’s sent to the user
Once you enable the Prompt Security integration in Portkey, every LLM request is automatically secured on both ends. Before a user prompt reaches the model, it’s scanned and sanitized through Prompt Security’s Protect Prompt engine, blocking malicious inputs or redacting sensitive information. Once the model generates a response, that output flows through Protect Response, which filters harmful content, detects jailbreak attempts, and ensures only safe, compliant responses are returned to the user.
All of this happens seamlessly within the Portkey Gateway, without additional setup or rewrites. This gives you full visibility, traceability, and control — all while offloading the heavy lifting of prompt and response inspection to a specialized, production-grade guardrail provider.
For more information on how to implement this, please check our detailed documentation.
You can also view guardrail results directly in Portkey Logs, with:
- An overview of how many checks passed or failed
- A verdict for each individual guardrail check
- The latency for every guardrail call, so you can track the performance impact
This gives your team clear, actionable insight into how your guardrails are performing, request by request.
Secure your AI stack with Prompt Security
As LLMs power more critical workflows, the need for safety, control, and real-time intervention becomes non-negotiable. With Portkey, you don’t need to build guardrails from scratch as they’re already part of your Gateway.
And with integrations like Prompt Security, you can level up protection instantly, securing both user inputs and model outputs with minimal setup.