

Retries, fallbacks, and circuit breakers in LLM apps: what to use when
Retries and fallbacks aren’t enough to keep AI systems stable under real-world load. This guide breaks down how circuit breakers work, when to use them, and how to design for failure across your LLM stack.
In AI applications handling millions of LLM or agent requests, failure is routine. Transient timeouts, flaky responses, and sudden spikes in latency are everyday events when you're routing through external APIs at scale.
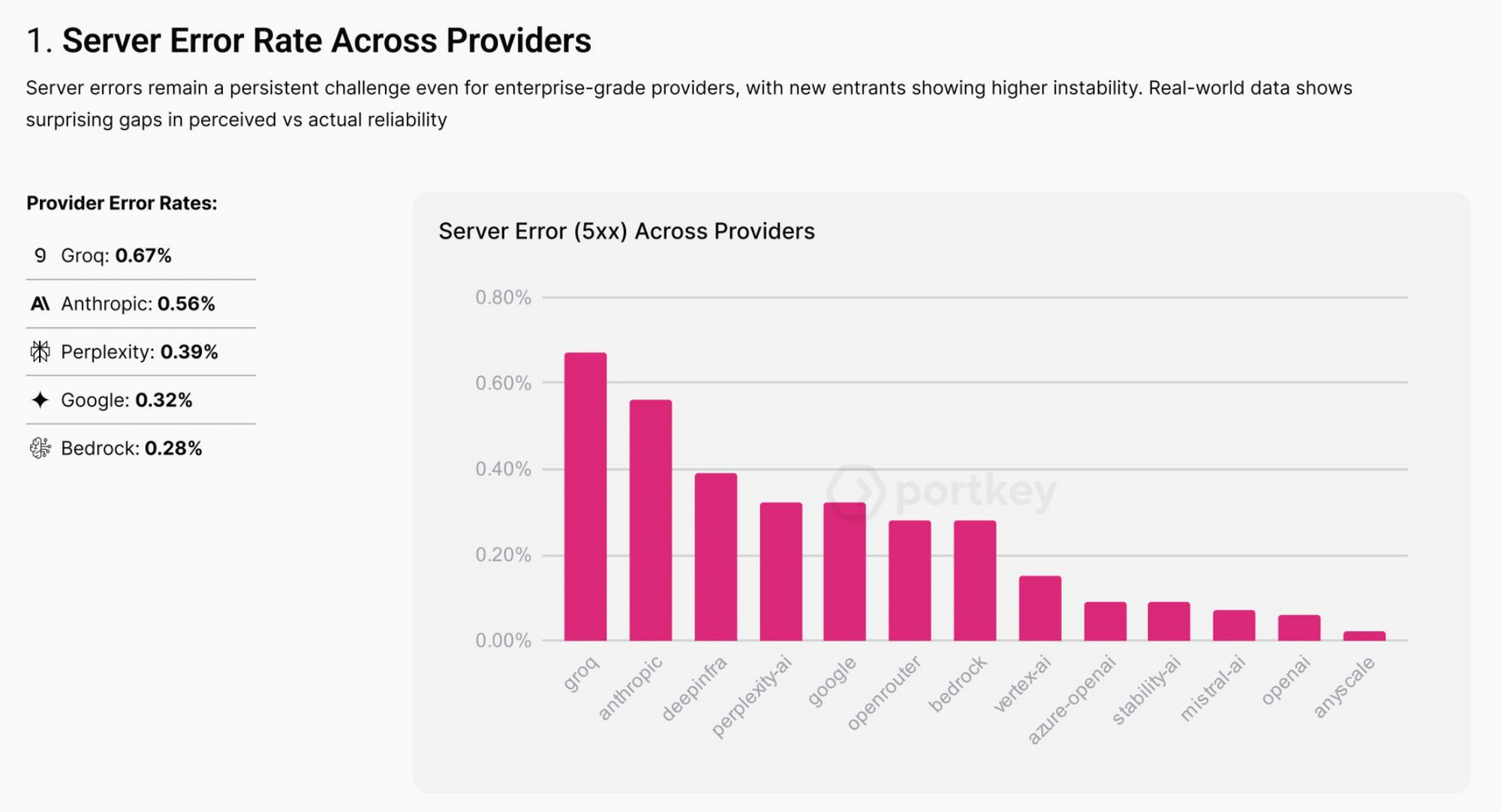
Teams usually start with reactive strategies like retries and fallbacks, as a response to failures, as and when they happen. And it generally works well with short-lived issues.
But when failure is systemic, you need a proactive approach. Something that watches for signs of trouble and steps in before things get worse.
Why failure handling matters in AI systems
LLM apps and AI agents are built on top of remote APIs — foundation models, vector stores, RAG pipelines, tools, and orchestrators. Every call adds another point of failure. And as usage scales, so does the likelihood of something going wrong.
These failures are often silent and short-lived: a timeout here, a delayed response there. But they hit at the worst moments, i.e., during peak traffic, inside multi-step workflows, or when an agent is mid-task.
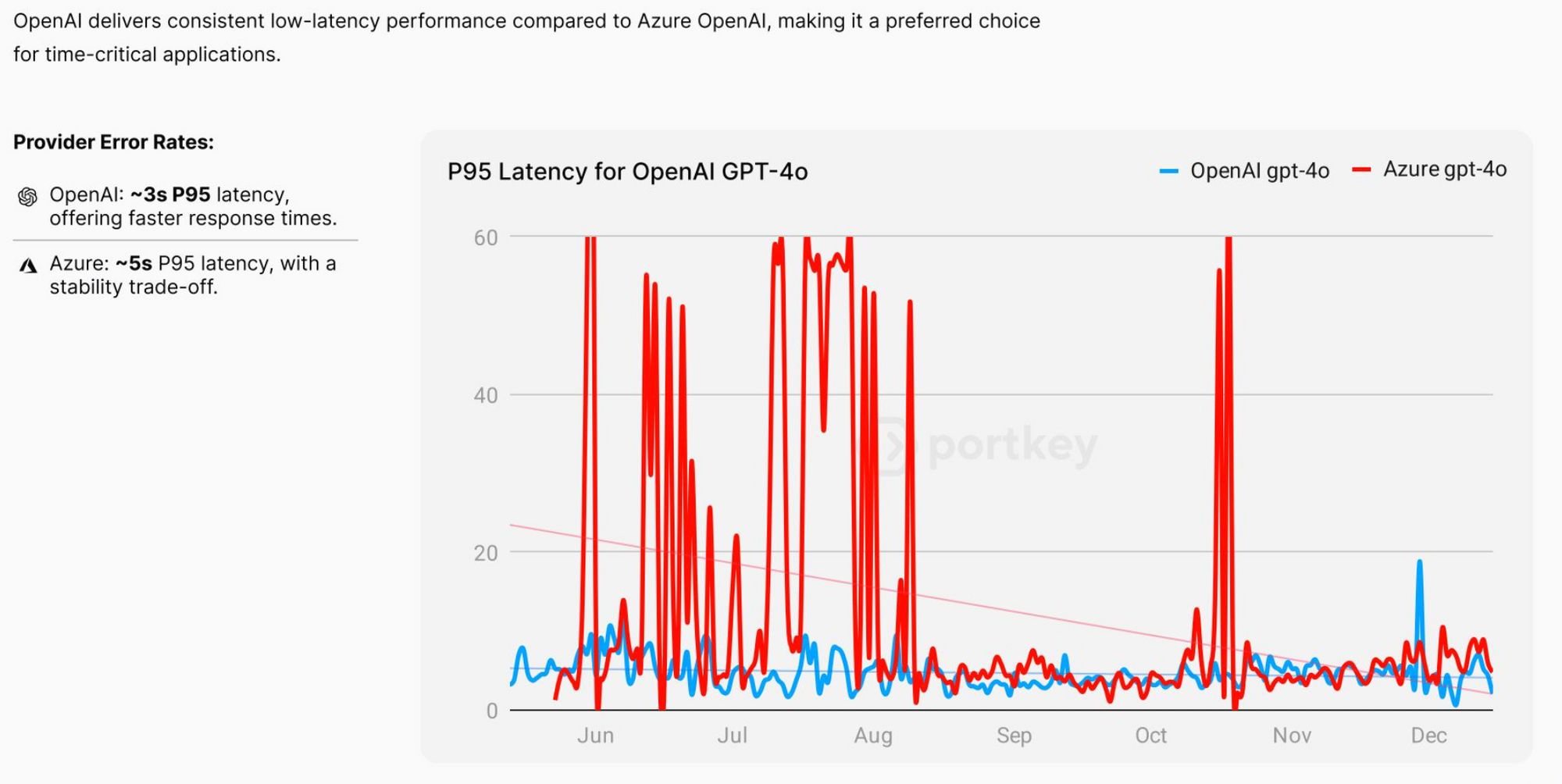
The problem isn’t that these failures happen. The problem is what they trigger.
Why retries and fallbacks alone fall short
Retries and fallbacks are the first lines of defense in most AI applications. They're simple to set up and work well under specific conditions. But they are reactive mechanisms. And in high-volume systems, these strategies are not enough.
Retries are designed for temporary glitches, the kind that clear up in a few seconds:
- Network instability
- TLS handshake failures
- Cold starts in serverless model hosts
- Brief provider rate limits
- Token quota refresh delays
In these cases, retrying the same request after a delay often succeeds. Most retry systems use exponential backoff to increase the wait time between attempts, reducing the pressure on the provider. Some platforms also support Retry-After headers from the provider, which let you adjust the delay. This makes retries smarter, avoiding aggressive retry loops.
But here's the catch: retries don’t know when a failure is persistent. If the provider is down or degraded, retries just keep hammering the same endpoint. At scale, this turns into a retry storm, stacking up requests, driving up token usage, and slowing the entire system.
Fallbacks are designed to ensure continuity. If your primary provider fails, you switch to a secondary one. This helps in cases where a provider is temporarily overloaded, or when a cheaper model is good enough for degraded quality.
But fallbacks have a few blind spots too. They are also reactive. The system checks the primary every time, even if it’s failing, before routing to the fallback. This adds latency. The app waits for the timeout or error, then switches. In multi-hop agent chains, this delay compounds.
Fallbacks can also share the same failure domain. If the fallback is on the same infrastructure, behind the same provider or private endpoint, it might fail in exactly the same way.
Circuit breakers — what they are and how they work
Retries and fallbacks try to recover from failures. Circuit breakers prevent a bad situation from spiraling further. They are designed to monitor failure patterns and automatically cut off traffic to unhealthy components before the rest of the system is affected.
What circuit breakers do
At a high level, a circuit breaker monitors things like:
- Number of failed requests
- Rate of failures over time
- Specific failure status codes (e.g., 429, 502, 503)
If certain thresholds are crossed, the breaker trips. Once tripped:
- The failing provider or model is removed from the routing pool
- No more requests are sent to it for a fixed cooldown period
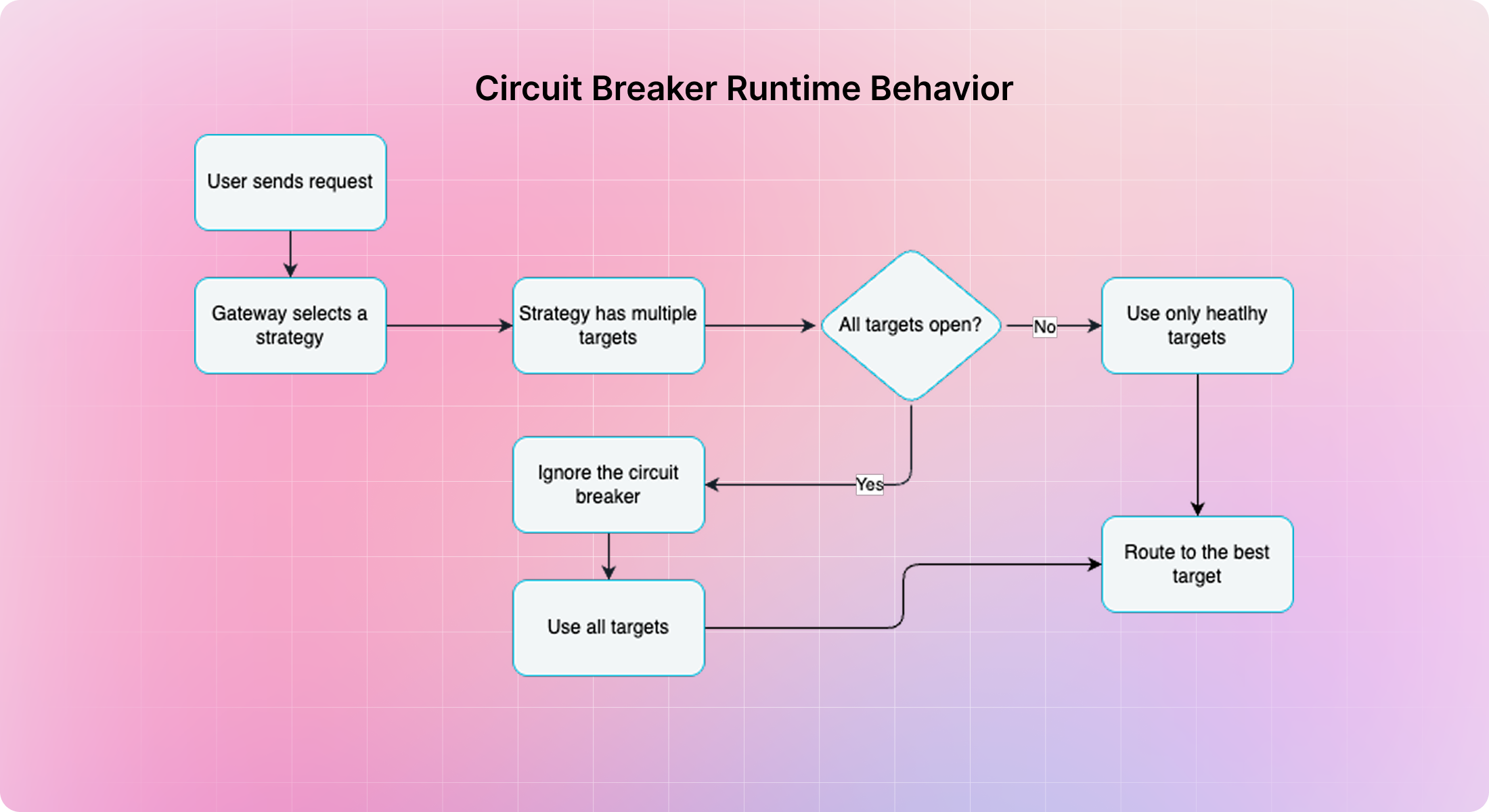
This mechanism avoids piling more traffic onto an already degraded service. It protects your fallbacks from getting overloaded too early, and it gives your system time to stabilize without developer intervention.
Each of these strategies serves a different purpose. They aren’t interchangeable, and one isn’t a replacement for the other. The key is understanding what kind of failure you’re dealing with and choosing the right response for that failure.
For example, imagine an LLM agent built for internal knowledge retrieval. During a provider outage, the summarization step starts returning timeouts. Retries are triggered, which briefly succeed for some calls, but overall performance degrades. Meanwhile, the fallback route takes longer because the system first waits for the retries to fail.
If a circuit breaker had been in place, it would have observed the rising failure rate and stopped traffic to the failing model much earlier. The fallback would have been triggered preemptively, without waiting for the retries to finish, and the system would have stayed responsive under pressure.
In high-scale environments, you rarely face just one type of failure. A transient glitch can turn into degraded service. A slow model can trigger retries and queue backups. This is why a layered approach matters. Retries help you recover from the small stuff. Fallbacks provide a plan B. And circuit breaker is the ultimate backup.
Try it out with Portkey
Portkey's AI Gateway gives you the building blocks to set this up without writing custom logic in every agent or workflow.
You can define retry policies with exponential backoff, build fallback chains across providers or models, and now, configure circuit breakers that detect failure patterns and stop traffic before things get worse.
Circuit breaker in Portkey lets you monitor error thresholds, failure rates, specific status codes, and more, all configurable per strategy. When a target becomes unhealthy, Portkey removes it from routing automatically and recovers once the cooldown is complete. No manual tuning needed.
This setup works across providers. Whether you're building a RAG pipeline, multi-step agent, or model router, Portkey helps you keep it resilient.
If you're handling traffic at scale or building anything critical on top of LLMs, don’t wait for a major failure to rethink resilience. You can try this setup directly in Portkey. Or we can give you a platform walkthrough.