

Real-time Guardrails vs Batch Evals: Understanding Safety Mechanisms in LLM Applications
In the world of Large Language Model (LLM) applications, ensuring quality, safety, and reliability requires different types of safety mechanisms at different stages. Two distinct approaches serve unique purposes: real-time guardrails and batch evaluations (evals). Let's understand how they differ and why both matter.
Real-time Guardrails: Automated Runtime Protection
Real-time guardrails are automated systems that actively monitor and control LLM interactions during production. Like a circuit breaker in an electrical system, they can instantly intervene when necessary.
Key Characteristics of Real-time Guardrails:
- Runtime Protection
- Operates during actual API calls
- Provides immediate intervention capabilities
- Can prevent problematic requests from reaching the LLM
- Enables response filtering before reaching the end-user - Bidirectional Filtering
- Pre-request validation: Checks input prompts for inappropriate content, security risks, or other concerns
- Post-response validation: Analyzes LLM outputs for quality, safety, and compliance
- Enables immediate action based on validation results - Actionable Outcomes
- Operates during actual API calls
- Provides immediate intervention capabilities
- Can prevent problematic requests from reaching the LLM
- Enables response filtering before reaching the end-user
Adaptive Decision Making
if (guardrail_check_fails):
if (severity == "high"):
cancel_request()
elif (severity ="medium"):
retry_with_different_model()
else:
log_warning()
proceed_with_request()Implementation Flow
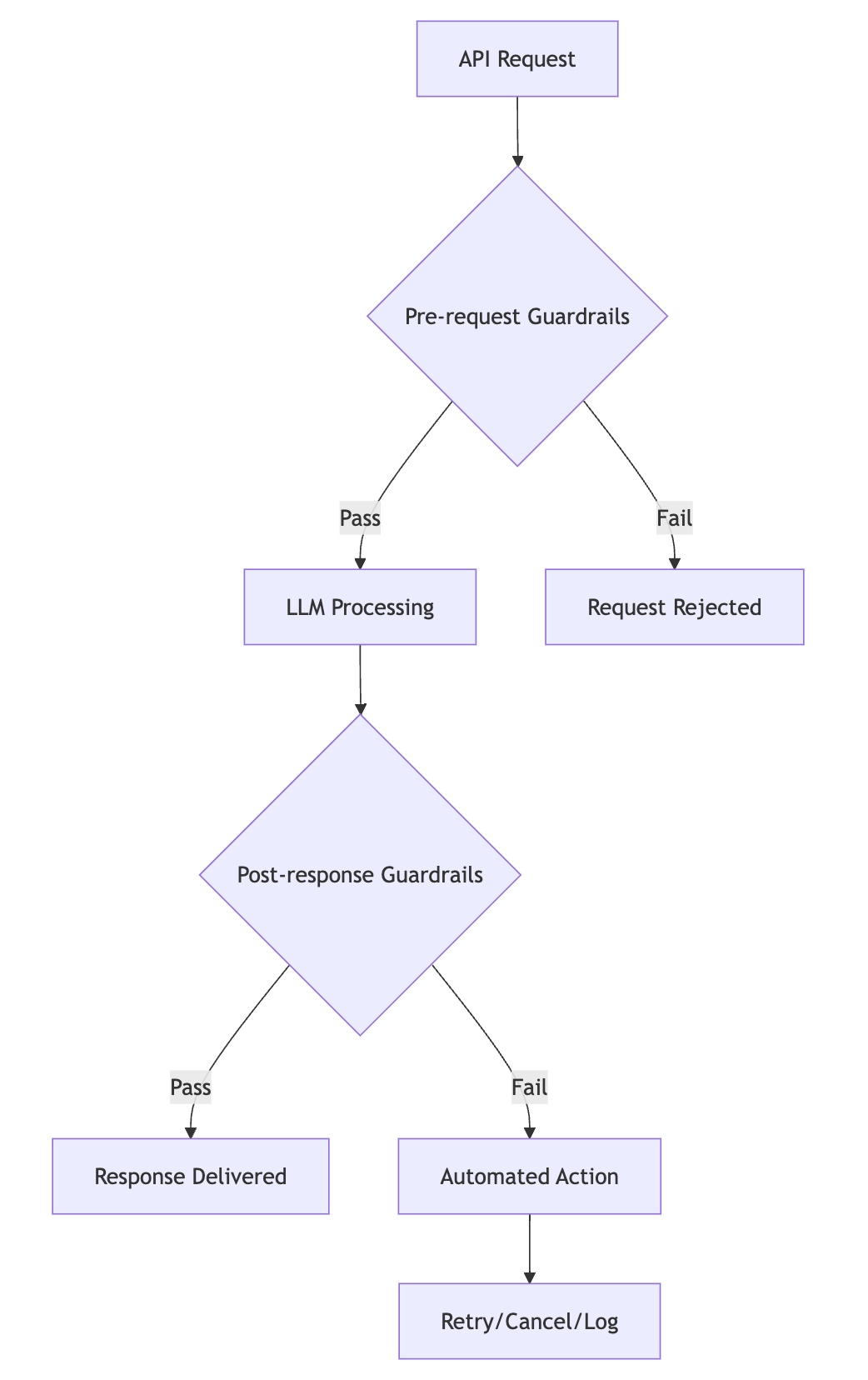
Batch Evals: Development-time Quality Assurance
Batch evaluations serve a different purpose - they're comprehensive testing suites run during development to validate and optimize LLM configurations.
Core Characteristics
- Development Phase Testing
- Runs on test datasets
- Processes multiple scenarios
- Measures various metrics
- Guides configuration decisions - Comprehensive Analysis
- Model performance comparison
- Parameter optimization
- Cost-efficiency assessment
- Quality benchmarking - Key Metrics
- Eval criteria refinement
- Guardrail optimization
- Model selection updates
- Parameter adjustments
Implementation Considerations
When implementing these safety mechanisms:
- Performance Impact
- Guardrails must be lightweight
- Minimal latency addition
- Efficient resource usage
- Quick decision-making - Reliability Requirements
- Handle traffic spikes
- Maintain performance
- Resource efficiency
- Cost optimization - Scaling Needs
- High availability
- Consistent performance
- Clear error handling
- Robust logging
Real-time guardrails and batch evals serve distinct but complementary purposes in LLM applications:
- Guardrails provide automated, real-time protection in production
- Evals ensure thorough quality assessment during development
Implementing both creates a comprehensive safety framework:
- Use evals to optimize configurations and understand performance
- Deploy guardrails to maintain runtime safety and quality
- Use production data to improve both systems continuously
This dual approach ensures both proactive and reactive protection, delivering reliable and safe AI-powered services.

