

How a model catalog accelerates LLM development
See how a model catalog simplifies governance and why it is essential for building and scaling LLM applications
As organizations race to integrate large language models (LLMs) into their products and workflows, managing access to these models is becoming increasingly complex. With dozens of providers, rapidly evolving capabilities, and varying cost-performance tradeoffs, teams need more than just API keys and documentation—they need structure.
In this blog, we’ll explore why a model catalog is essential to building and scaling LLM applications—and how it simplifies everything from governance to experimentation. We’ll also look at how Portkey’s model catalog brings all of this together in one place.
What is a model catalog?
A model catalog is a centralized registry of all the large language models an organization has access to, across all providers, versions, and capabilities. It is a searchable directory that tells your teams which models are available, what they cost, and what features they support.
A model catalog typically includes:
- Provider (e.g., OpenAI, Anthropic, Mistral)
- Model name and version
- Input/output token limits
- Modalities
Why model catalogs are critical for LLM apps
As LLM adoption grows across teams, unstructured access quickly leads to chaos—unaudited usage, ballooning costs, and inconsistent performance. A model catalog solves this by becoming the single source of truth for LLM access, governance, and experimentation. Here’s why it’s critical:
1. Centralized governance at scale
A model catalog allows you to enforce rate limits and budget caps at both the organization and team levels. Instead of relying on per-API configurations scattered across services, you can centrally define how much usage is allowed, by whom, and on which models. This is essential for maintaining control as usage scales across multiple teams.
2. Easier access control and provisioning
With a model catalog, you can define who gets access to which models based on roles, teams, or environments (dev/staging/prod). This eliminates the risk of unauthorized or accidental usage of premium models and ensures compliance with internal and external policies.
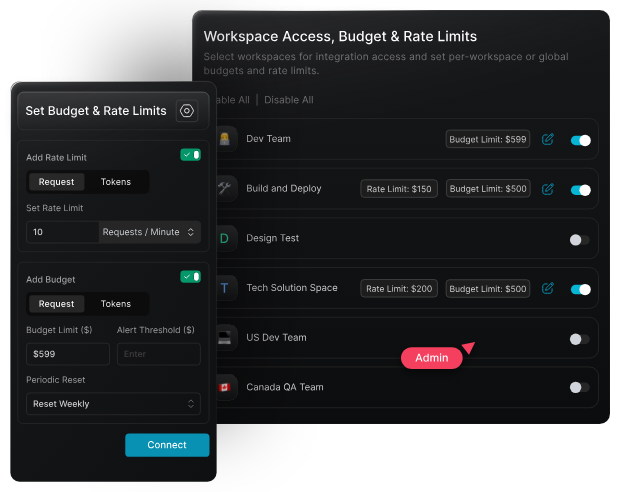
Provisioning access becomes significantly easier, too—you can onboard new teams, restrict experimental models, or allow sandbox access without touching the underlying provider accounts.
3. Better model discovery
A centralized catalog helps developers discover what models are available and what they’re best suited for. Instead of hunting through provider documentation or internal Notion pages, teams can filter models by capabilities (e.g., supports vision, low-latency, low-cost) and select the best one for the task at hand.
4. Standardization and portability
Model catalogs enforce consistent access patterns across providers. Whether you’re calling GPT-4, Claude, or Mistral, the interface remains the same. This abstraction layer not only reduces integration time but also makes switching providers easier, critical for cost and performance optimization.
5. Safer, faster development workflows
By centralizing all model metadata and access controls, teams spend less time guessing and more time building. The model catalog helps reduce errors from unsupported capabilities, avoid deprecated models, and move faster with guardrails in place.
How Portkey’s model catalog helps you ship LLM apps faster
Portkey’s model catalog is purpose-built to simplify how teams discover, control, and use LLMs at scale. Instead of juggling different API docs, credentials, or integration patterns, Portkey gives you a centralized, always-up-to-date registry of all supported models.
Here’s how it helps your team move faster and stay in control:
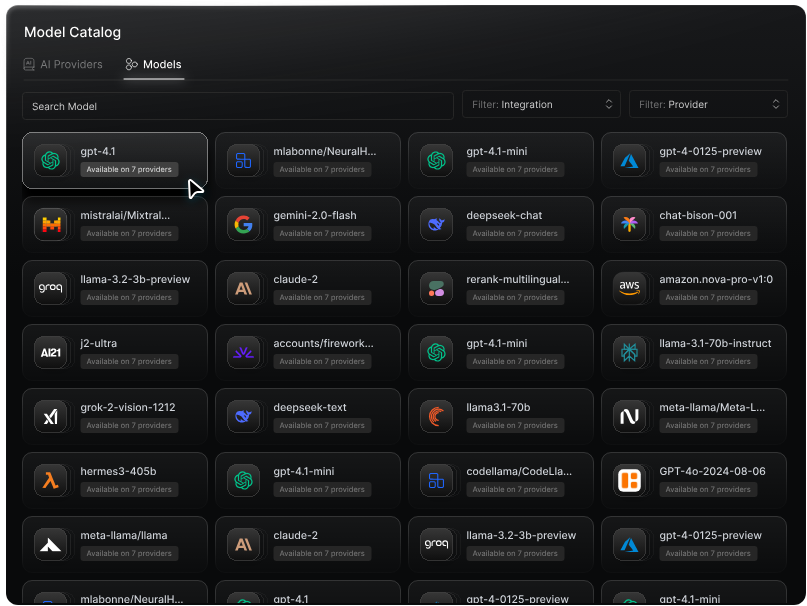
Unified model discovery
Portkey’s model catalog includes models across providers like OpenAI, Anthropic, Mistral, Cohere, and more. Each entry comes with rich metadata:
- Token limits, input/output constraints
- Pricing and regions
- Feature support (e.g., vision, function calling, streaming)
You can search and filter models based on these properties to instantly find the right model for your use case.
Org-wide governance
With Portkey, you can set rate limits and budget caps at the org, team, or key level. This makes it easy to enforce usage policies:
- Cap monthly spend per team
- Restrict access to high-cost models like GPT-4 or Claude 3 Opus
- Throttle traffic to avoid overuse or abuse
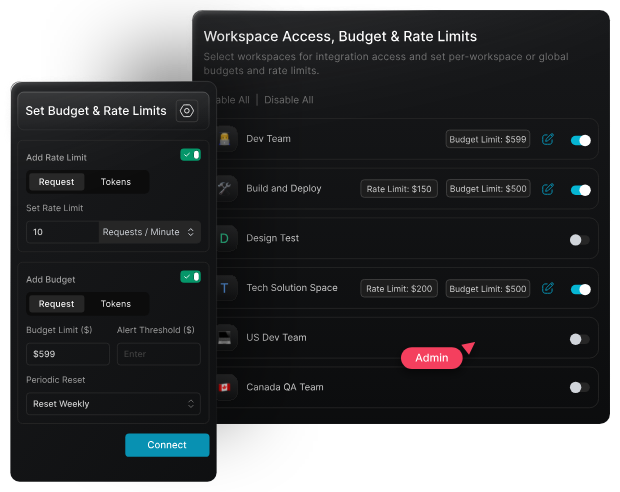
All of this is managed via the Portkey dashboard, no need to go into each provider’s settings.
Access control
Easily control who can use which models, and in what environments. You can grant different access rights for dev vs. production environments, or limit experimental models to specific users. This helps avoid accidental production usage of expensive or untested models.
Fast experimentation and fallback
Portkey makes it easy to test prompts across multiple models in the same interface. Whether through the dashboard or API, you can compare responses, latency, and costs side by side. You can even define fallback chains—e.g., if GPT-4 fails or times out, automatically route to Claude or Mistral.
API-level abstraction and portability
With a consistent API across all models, you don’t need to rewrite code when switching from one model to another. You define the model slug (e.g., openai:gpt-4-turbo) and Portkey handles the rest, including retries, streaming, and observability.
Start implementing the model catalog in your organization!
A model catalog is the connective tissue that lets organisations turn a growing list of LLMs into a coherent, governable, and cost-efficient platform. By centralising discovery, enforcing rate- and budget-limits, and standardising access, it removes the friction that usually slows teams down.

Portkey’s model catalog bundles all of those advantages into one easily integrated layer. Teams get a single, searchable registry; leaders get org- and team-level controls; everyone benefits from faster iteration and clearer governance.
If you’re ready to scale LLM usage without losing track of models, spend, or performance, Portkey’s model catalog is the place to start. See how quickly you can ship your next LLM feature.